20 KiB
DeepSeek-R1

Lien vers article scientifique👁️
English | Français
1. Introduction
Nous vous présentons nos modèles de raisonnement de première génération, DeepSeek-R1-Zero et DeepSeek-R1.
DeepSeek-R1-Zero, un modèle entraîné à l’aide d’apprentissage par renforcement (Reinforcement Learning, RL) à grande échelle, sans fine-tuning supervisé (Supervised fine-tuning, STF) comme étape préliminaire, a fait preuve d’une performance remarquable en matière de raisonnement complexe. À l’aide de RL, DeepSeek-R1-Zero a naturellement émergé avec de nombreux comportements de raisonnement puissants et intéressants. Cependant, ce modèle a rencontré plusieurs défis, tels que la répétition infinie, la mauvaise lisibilité et le mélange de langues.
Pour résoudre ces problèmes et améliorer les performances de raisonnement, nous introduisons DeepSeek-R1, qui incorpore des données de cold-start avant le RL. Ce modèle atteint des performances comparables à celles d’OpenAI-o1 pour les tâches de mathématiques, de code et de raisonnement complexe.
Afin de soutenir la communauté des chercheurs, nous avons ouvert DeepSeek-R1-Zero, DeepSeek-R1, ainsi que six modèles denses distillés à partir de DeepSeek-R1, basés sur Llama et Qwen. Parmi ces modèles, DeepSeek-R1-Distill-Qwen-32B surpasse OpenAI-o1-mini sur différents benchmarks, atteignant de nouveaux résultats de pointe pour les modèles denses.
NOTE: Avant d'exécuter notre série de modèles DeepSeek-R1 localement, nous vous recommandons vivement de prendre connaissance de la section Recommandations pratiques.
2. Synthèse du modèle
Post-Entraînement: Apprentissage par renforcement à grande échelle sur le modèle de base
-
Nous appliquons directement le RL sur le modèle de base sans devoir faire du fine-tuning supervisé (STF) comme étape préliminaire. Cette approche permet au modèle d'explorer la chaîne de pensée (chain-of-thought, CoT) pour résoudre des problèmes complexes, ce qui a conduit au développement de DeepSeek-R1-Zero. DeepSeek-R1-Zero démontre des capacités telles que l'auto-vérification, la réflexion et la génération de longs CoT, marquant ainsi une étape importante pour la communauté des chercheurs. Il s'agit notamment du premier projet de recherche ouvert à valider le fait que les capacités de raisonnement des LLM peuvent être encouragées uniquement par le biais de la RL, sans qu'il soit nécessaire de recourir à la SFT. Cette percée ouvre la voie à de futures avancées dans ce domaine.
-
Nous présentons notre processus de développement de DeepSeek-R1. Ce pipeline comprend deux étapes de RL visant à découvrir des modèles de raisonnement améliorés et à s'aligner sur les préférences humaines, ainsi que deux étapes de SFT qui servent de germe pour les capacités de raisonnement et de non-raisonnement du modèle. Nous pensons que ce pipeline sera bénéfique à l'industrie en créant de meilleurs modèles.
Distillation: Les modèles plus petits peuvent être puissants aussi
- Nous démontrons que les modèles de raisonnement des grands modèles peuvent être distillés dans des modèles réduits, ce qui permet d'obtenir de meilleures performances par rapport aux modèles de raisonnement découverts par le biais du RL sur les petits modèles. Le modèle Open-Source DeepSeek-R1, ainsi que son API, permettra à la communauté des chercheurs de distiller de meilleurs modèles réduits à l'avenir.
- En utilisant les données de raisonnement générées par DeepSeek-R1, nous avons fine-tuné plusieurs modèles denses qui sont largement utilisés dans la communauté des chercheurs. Les résultats d'évaluation montrent que les modèles distillés sont particulièrement performants sur les benchmarks. Nous mettons à la disposition de la communauté (en Open-Source) plusieurs modèles de 1.5B, 7B, 8B, 14B, 32B et 70B paramètres basés sur les séries Qwen2.5 et Llama3.
3. Téléchargements
Modèles DeepSeek-R1
| Modèle | #Total Params | #Params activés | Longueur du contexte | Télécharger |
|---|---|---|---|---|
| DeepSeek-R1-Zero | 671B | 37B | 128K | 🤗 HuggingFace |
| DeepSeek-R1 | 671B | 37B | 128K | 🤗 HuggingFace |
NOTE : 1B équivaut à un milliard
DeepSeek-R1-Zero et DeepSeek-R1 ont été entraînés en se basant sur DeepSeek-V3-Base. Pour plus de détails sur l'architecture du modèle, veuillez vous référer au dépôt DeepSeek-V3.
Modèles DeepSeek-R1-Distill
| Modèle | Modèle de base | Télécharger |
|---|---|---|
| DeepSeek-R1-Distill-Qwen-1.5B | Qwen2.5-Math-1.5B | 🤗 HuggingFace |
| DeepSeek-R1-Distill-Qwen-7B | Qwen2.5-Math-7B | 🤗 HuggingFace |
| DeepSeek-R1-Distill-Llama-8B | Llama-3.1-8B | 🤗 HuggingFace |
| DeepSeek-R1-Distill-Qwen-14B | Qwen2.5-14B | 🤗 HuggingFace |
| DeepSeek-R1-Distill-Qwen-32B | Qwen2.5-32B | 🤗 HuggingFace |
| DeepSeek-R1-Distill-Llama-70B | Llama-3.3-70B-Instruct | 🤗 HuggingFace |
Les modèles DeepSeek-R1-Distill ont été fine-tunés en se basant sur des modèles open-source avec des données générés par DeepSeek-R1. Nous avons légérement modifié leurs configuration et tokenizers. Veuillez utiliser nos configurations pour ces modèles.
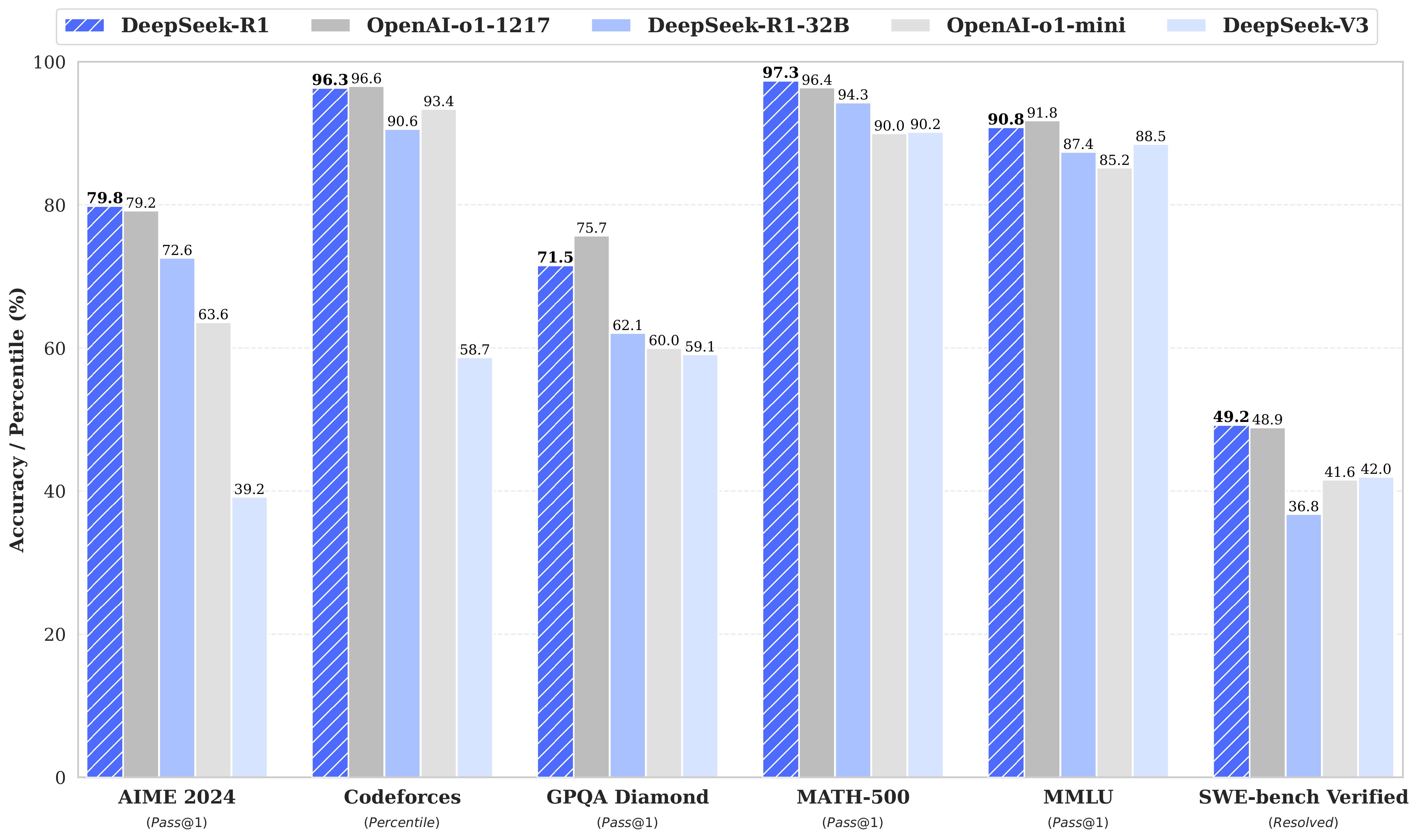
4. Résultats d'évaluation
Évaluation de DeepSeek-R1-Evaluation
Pour tous nos modèles, la longueur maximale de génération est mise à 32'768 token. Pour les benchmarks utilisant de l'échantillonnage, nous avons utilisé une température de 0.6, une top-p valeur de 0.95 et une génération de 64 réponses par requête pour estimer pass@1.
| Category | Benchmark (Metric) | Claude-3.5-Sonnet-1022 | GPT-4o 0513 | DeepSeek V3 | OpenAI o1-mini | OpenAI o1-1217 | DeepSeek R1 |
|---|---|---|---|---|---|---|---|
| Architecture | - | - | MoE | - | - | MoE | |
| # Activated Params | - | - | 37B | - | - | 37B | |
| # Total Params | - | - | 671B | - | - | 671B | |
| English | MMLU (Pass@1) | 88.3 | 87.2 | 88.5 | 85.2 | 91.8 | 90.8 |
| MMLU-Redux (EM) | 88.9 | 88.0 | 89.1 | 86.7 | - | 92.9 | |
| MMLU-Pro (EM) | 78.0 | 72.6 | 75.9 | 80.3 | - | 84.0 | |
| DROP (3-shot F1) | 88.3 | 83.7 | 91.6 | 83.9 | 90.2 | 92.2 | |
| IF-Eval (Prompt Strict) | 86.5 | 84.3 | 86.1 | 84.8 | - | 83.3 | |
| GPQA-Diamond (Pass@1) | 65.0 | 49.9 | 59.1 | 60.0 | 75.7 | 71.5 | |
| SimpleQA (Correct) | 28.4 | 38.2 | 24.9 | 7.0 | 47.0 | 30.1 | |
| FRAMES (Acc.) | 72.5 | 80.5 | 73.3 | 76.9 | - | 82.5 | |
| AlpacaEval2.0 (LC-winrate) | 52.0 | 51.1 | 70.0 | 57.8 | - | 87.6 | |
| ArenaHard (GPT-4-1106) | 85.2 | 80.4 | 85.5 | 92.0 | - | 92.3 | |
| Code | LiveCodeBench (Pass@1-COT) | 33.8 | 34.2 | - | 53.8 | 63.4 | 65.9 |
| Codeforces (Percentile) | 20.3 | 23.6 | 58.7 | 93.4 | 96.6 | 96.3 | |
| Codeforces (Rating) | 717 | 759 | 1134 | 1820 | 2061 | 2029 | |
| SWE Verified (Resolved) | 50.8 | 38.8 | 42.0 | 41.6 | 48.9 | 49.2 | |
| Aider-Polyglot (Acc.) | 45.3 | 16.0 | 49.6 | 32.9 | 61.7 | 53.3 | |
| Math | AIME 2024 (Pass@1) | 16.0 | 9.3 | 39.2 | 63.6 | 79.2 | 79.8 |
| MATH-500 (Pass@1) | 78.3 | 74.6 | 90.2 | 90.0 | 96.4 | 97.3 | |
| CNMO 2024 (Pass@1) | 13.1 | 10.8 | 43.2 | 67.6 | - | 78.8 | |
| Chinese | CLUEWSC (EM) | 85.4 | 87.9 | 90.9 | 89.9 | - | 92.8 |
| C-Eval (EM) | 76.7 | 76.0 | 86.5 | 68.9 | - | 91.8 | |
| C-SimpleQA (Correct) | 55.4 | 58.7 | 68.0 | 40.3 | - | 63.7 |
Évaluation des modèles distillés
| Model | AIME 2024 pass@1 | AIME 2024 cons@64 | MATH-500 pass@1 | GPQA Diamond pass@1 | LiveCodeBench pass@1 | CodeForces rating |
|---|---|---|---|---|---|---|
| GPT-4o-0513 | 9.3 | 13.4 | 74.6 | 49.9 | 32.9 | 759 |
| Claude-3.5-Sonnet-1022 | 16.0 | 26.7 | 78.3 | 65.0 | 38.9 | 717 |
| o1-mini | 63.6 | 80.0 | 90.0 | 60.0 | 53.8 | 1820 |
| QwQ-32B-Preview | 44.0 | 60.0 | 90.6 | 54.5 | 41.9 | 1316 |
| DeepSeek-R1-Distill-Qwen-1.5B | 28.9 | 52.7 | 83.9 | 33.8 | 16.9 | 954 |
| DeepSeek-R1-Distill-Qwen-7B | 55.5 | 83.3 | 92.8 | 49.1 | 37.6 | 1189 |
| DeepSeek-R1-Distill-Qwen-14B | 69.7 | 80.0 | 93.9 | 59.1 | 53.1 | 1481 |
| DeepSeek-R1-Distill-Qwen-32B | 72.6 | 83.3 | 94.3 | 62.1 | 57.2 | 1691 |
| DeepSeek-R1-Distill-Llama-8B | 50.4 | 80.0 | 89.1 | 49.0 | 39.6 | 1205 |
| DeepSeek-R1-Distill-Llama-70B | 70.0 | 86.7 | 94.5 | 65.2 | 57.5 | 1633 |
5. Chatbot en ligne et plateforme API
Vous pouvez utiliser DeepSeek-R1 sur le site officiel de DeepSeek: chat.deepseek.com, en appuyant sur le bouton "DeepThink"
Nous fournissons aussi une API compatible avec OpenAI sur la plateforme DeepSeek : platform.deepseek.com
6. Comment exécuter localement
Modèles DeepSeek-R1
Veuillez visiter le repo DeepSeek-V3 pour plus d'informations sur l'exécution locale de DeepSeek-R1.
NOTE: les Transformers de Hugging Face ne sont pas encore supportés.
Modèles DeepSeek-R1-Distill
Les modèles DeepSeek-R1-Distill peuvent être utilisés de la même manière que les modèles Qwen ou Llama.
Par exemple, vous pouvez facilement démarrer un service en utilisant vLLM:
vllm serve deepseek-ai/DeepSeek-R1-Distill-Qwen-32B --tensor-parallel-size 2 --max-model-len 32768 --enforce-eager
Vous pouvez également démarrer un service avec SGLang
python3 -m sglang.launch_server --model deepseek-ai/DeepSeek-R1-Distill-Qwen-32B --trust-remote-code --tp 2
Recommandations pratiques
Nous vous recommandons de vous adhérer aux configurations suivantes pour la série de modèles DeepSeek-R1, y compris pour les benchmarks, pour atteindre les performances prévues:
- Utiliser une température dans l'intervalle [0.5, 0.7] (0.6 est recommandé) pour éviter des répétitions sans fin ou des réponses incohérentes.
- Éviter d'ajouter des prompts systèmes; Toute instruction doit être comprise dans le prompt utilisateur.
- Pour les problèmes mathématiques, il est fortement conseillé d'inclure une consigne dans votre prompt tel que: "Veuillez raisonner étape par étape et mettez votre réponse dans \boxed{}."
- Pour évaluer les performances du modèle, nous vous conseillons de faire plusieurs essais et de prendre la moyenne des résultats.
7. Licence
Ce dépôt de code et les poids des modèles sont sous une Licence MIT. La série de modèles DeepSeek-R1 prend en charge l'utilisation à des fins commerciales, permet toutes les modifications et les travaux dérivés, y compris, mais pas uniquement, la distillation pour l'entraînement d'autres LLM. À noter que :
- DeepSeek-R1-Distill-Qwen-1.5B, DeepSeek-R1-Distill-Qwen-7B, DeepSeek-R1-Distill-Qwen-14B et DeepSeek-R1-Distill-Qwen-32B sont dérivés de la série Qwen-2.5, qui sont à l'origine sous une Licence Apache 2.0, et ont été peufinés avec 800k échantillons analysés avec DeepSeek-R1.
- DeepSeek-R1-Distill-Llama-8B est dérivé de Llama3.1-8B-Base qui est à l'origine sous une licence llama3.1.
- DeepSeek-R1-Distill-Llama-70B est dérivé de Llama3.3-70B-Instruct qui est à l'origine sous une licence llama3.3.
8. Citation
@misc{deepseekai2025deepseekr1incentivizingreasoningcapability,
title={DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning},
author={DeepSeek-AI and Daya Guo and Dejian Yang and Haowei Zhang and Junxiao Song and Ruoyu Zhang and Runxin Xu and Qihao Zhu and Shirong Ma and Peiyi Wang and Xiao Bi and Xiaokang Zhang and Xingkai Yu and Yu Wu and Z. F. Wu and Zhibin Gou and Zhihong Shao and Zhuoshu Li and Ziyi Gao and Aixin Liu and Bing Xue and Bingxuan Wang and Bochao Wu and Bei Feng and Chengda Lu and Chenggang Zhao and Chengqi Deng and Chenyu Zhang and Chong Ruan and Damai Dai and Deli Chen and Dongjie Ji and Erhang Li and Fangyun Lin and Fucong Dai and Fuli Luo and Guangbo Hao and Guanting Chen and Guowei Li and H. Zhang and Han Bao and Hanwei Xu and Haocheng Wang and Honghui Ding and Huajian Xin and Huazuo Gao and Hui Qu and Hui Li and Jianzhong Guo and Jiashi Li and Jiawei Wang and Jingchang Chen and Jingyang Yuan and Junjie Qiu and Junlong Li and J. L. Cai and Jiaqi Ni and Jian Liang and Jin Chen and Kai Dong and Kai Hu and Kaige Gao and Kang Guan and Kexin Huang and Kuai Yu and Lean Wang and Lecong Zhang and Liang Zhao and Litong Wang and Liyue Zhang and Lei Xu and Leyi Xia and Mingchuan Zhang and Minghua Zhang and Minghui Tang and Meng Li and Miaojun Wang and Mingming Li and Ning Tian and Panpan Huang and Peng Zhang and Qiancheng Wang and Qinyu Chen and Qiushi Du and Ruiqi Ge and Ruisong Zhang and Ruizhe Pan and Runji Wang and R. J. Chen and R. L. Jin and Ruyi Chen and Shanghao Lu and Shangyan Zhou and Shanhuang Chen and Shengfeng Ye and Shiyu Wang and Shuiping Yu and Shunfeng Zhou and Shuting Pan and S. S. Li and Shuang Zhou and Shaoqing Wu and Shengfeng Ye and Tao Yun and Tian Pei and Tianyu Sun and T. Wang and Wangding Zeng and Wanjia Zhao and Wen Liu and Wenfeng Liang and Wenjun Gao and Wenqin Yu and Wentao Zhang and W. L. Xiao and Wei An and Xiaodong Liu and Xiaohan Wang and Xiaokang Chen and Xiaotao Nie and Xin Cheng and Xin Liu and Xin Xie and Xingchao Liu and Xinyu Yang and Xinyuan Li and Xuecheng Su and Xuheng Lin and X. Q. Li and Xiangyue Jin and Xiaojin Shen and Xiaosha Chen and Xiaowen Sun and Xiaoxiang Wang and Xinnan Song and Xinyi Zhou and Xianzu Wang and Xinxia Shan and Y. K. Li and Y. Q. Wang and Y. X. Wei and Yang Zhang and Yanhong Xu and Yao Li and Yao Zhao and Yaofeng Sun and Yaohui Wang and Yi Yu and Yichao Zhang and Yifan Shi and Yiliang Xiong and Ying He and Yishi Piao and Yisong Wang and Yixuan Tan and Yiyang Ma and Yiyuan Liu and Yongqiang Guo and Yuan Ou and Yuduan Wang and Yue Gong and Yuheng Zou and Yujia He and Yunfan Xiong and Yuxiang Luo and Yuxiang You and Yuxuan Liu and Yuyang Zhou and Y. X. Zhu and Yanhong Xu and Yanping Huang and Yaohui Li and Yi Zheng and Yuchen Zhu and Yunxian Ma and Ying Tang and Yukun Zha and Yuting Yan and Z. Z. Ren and Zehui Ren and Zhangli Sha and Zhe Fu and Zhean Xu and Zhenda Xie and Zhengyan Zhang and Zhewen Hao and Zhicheng Ma and Zhigang Yan and Zhiyu Wu and Zihui Gu and Zijia Zhu and Zijun Liu and Zilin Li and Ziwei Xie and Ziyang Song and Zizheng Pan and Zhen Huang and Zhipeng Xu and Zhongyu Zhang and Zhen Zhang},
year={2025},
eprint={2501.12948},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2501.12948},
}
9. Contact
Si vous avez des questions, créez un issue ou contactez-nous à service@deepseek.com.