7.8 KiB
![]()
[🏠 主页] | [🤖 在线体验] | [🤗 模型下载] | [📄 英文版]
1. Deepseek Coder简介
Deepseek Coder 包括一系列高级语言模型,这些模型在87%的代码和13%的中英文自然语言数据上进行了预训练,共2T的单词。 Deepseek Coder提供各种参数大小的代码模型,范围从1B到33B版本。每个模型都在项目级代码数据上进行预训练,采用16K的窗口大小和额外的Fill-in-the-blank任务,以支持项目级别的代码补全和填充。 在代码能力方面,Deepseek Coder在多种编程语言和各种测试基准测试上都达到了目前开源代码模型的最优性能。
-
大量的训练数据:在2T单词上训练,包括87%的代码和13%的英文和中文语言数据。
-
高度灵活且可扩展:提供1B、7B和33B的模型大小,使用户能够选择最适合其需求的模型。
-
卓越的模型性能:在 HumanEval-X, MultiPL-E, MBPP, DS-1000, 和 APPS 基准测试上,DeepSeek Coder在公开可用的代码模型中性能最优。
-
先进的代码补全能力:采用16K的窗口大小和Fill-in-the-blank训练任务,支持项目级代码补全和填充任务。
2. 数据处理和模型训练
数据处理
- 步骤1:从GitHub收集代码数据,并采用与StarcoderData相同的过滤规则来筛选数据。
- 步骤2:解析同一仓库中文件的依赖关系,根据它们的依赖关系重新排列文件位置。
- 步骤3:组织依赖文件以形成单一示例,并使用仓库级别的minhash进行去重。
- 步骤4:进一步过滤掉低质量的代码,例如语法错误或可读性差的代码。

模型训练
-
步骤1:首先使用处理后数据进行预训练,该数据由87%的代码、10%与代码相关的语言数据(Github Markdown和Stack Exchange)以及3%与代码无关的中文语言数据组成。在此步骤中,采用1.8T的单词和4K的窗口大小进行模型预训练。
-
步骤2:扩展的窗口至16K并使用额外的200B单词进一步的进行预训练,从而得到基础版本模型(DeepSeek-Coder-Base)。
-
步骤3:使用300M单词的指令数据进行微调,得到经过指令调优的模型(DeepSeek-Coder-Instruct)。

3. 下载和环境依赖
Deepseek Coder 最初是在 Pytorch 中实现并在A100进行训练的。我们提供了基于Hai-LLM的 pytorch 兼容版本,支持transformers(3.34+),以便在其他GPU平台上使用。
同时模型的权重已上传到至🤗 huggingface。
环境依赖
Python 3.8+ / CUDA 11+ / PyTorch 2.0+ / transformers 3.34+.
4. 模型推理
请参考下面样例来使用我们模型:
代码补全
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("deepseek/deepseek-coder-7b")
device = 0 if torch.cuda.is_available() else -1
model = AutoModelForCausalLM.from_pretrained("deepseek/deepseek-coder-7b").to(device)
inputs = tokenizer("def hello_world():", return_tensors="pt").to(device)
outputs = model.generate(**inputs, max_length=128)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
代码填充
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("deepseek/deepseek-coder-7b")
device = 0 if torch.cuda.is_available() else -1
model = AutoModelForCausalLM.from_pretrained("deepseek/deepseek-coder-7b").to(device)
input_text = "<fim_prefix>def print_hello_world():\n <fim_suffix>\n print('Hello world!')<fim_middle>"
inputs = tokenizer.encode(input_text, return_tensors="pt").to(device)
outputs = model.generate(**inputs, max_length=128)
print(tokenizer.decode(outputs[0]))
仓库级别的代码补全
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("deepseek/deepseek-coder-7b")
input_text = """#utils.py
import torch
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import accuracy_score
def load_data():
iris = datasets.load_iris()
X = iris.data
y = iris.target
# Standardize the data
scaler = StandardScaler()
X = scaler.fit_transform(X)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# Convert numpy data to PyTorch tensors
X_train = torch.tensor(X_train, dtype=torch.float32)
X_test = torch.tensor(X_test, dtype=torch.float32)
y_train = torch.tensor(y_train, dtype=torch.int64)
y_test = torch.tensor(y_test, dtype=torch.int64)
return X_train, X_test, y_train, y_test
def evaluate_predictions(y_test, y_pred):
return accuracy_score(y_test, y_pred)
#model.py
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, TensorDataset
class IrisClassifier(nn.Module):
def __init__(self):
super(IrisClassifier, self).__init__()
self.fc = nn.Sequential(
nn.Linear(4, 16),
nn.ReLU(),
nn.Linear(16, 3)
)
def forward(self, x):
return self.fc(x)
def train_model(self, X_train, y_train, epochs, lr, batch_size):
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(self.parameters(), lr=lr)
# Create DataLoader for batches
dataset = TensorDataset(X_train, y_train)
dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True)
for epoch in range(epochs):
for batch_X, batch_y in dataloader:
optimizer.zero_grad()
outputs = self(batch_X)
loss = criterion(outputs, batch_y)
loss.backward()
optimizer.step()
def predict(self, X_test):
with torch.no_grad():
outputs = self(X_test)
_, predicted = outputs.max(1)
return predicted.numpy()
#main.py
from utils import load_data, evaluate_predictions
from model import IrisClassifier as Classifier
def main():
# Model training and evaluation
"""
inputs = tokenizer.encode(input_text, return_tensors="pt").to(device)
outputs = model.generate(**inputs, max_length=128)
print(tokenizer.decode(outputs[0]))
In the following scenario, the Deepseek-Coder 7B model effectively calls a class IrisClassifier and its member function from the model.py file, and also utilizes functions from the utils.py file, to correctly complete the main function inmain.py file for model training and evaluation.
在下面样例中,Deepseek-Coder 7B 模型有效地从 model.py 文件中调用了一个名为 IrisClassifier 的类及其成员函数,并利用了 utils.py 文件中的函数,以正确地完成main.py 文件中的模型的训练和评估的功能。
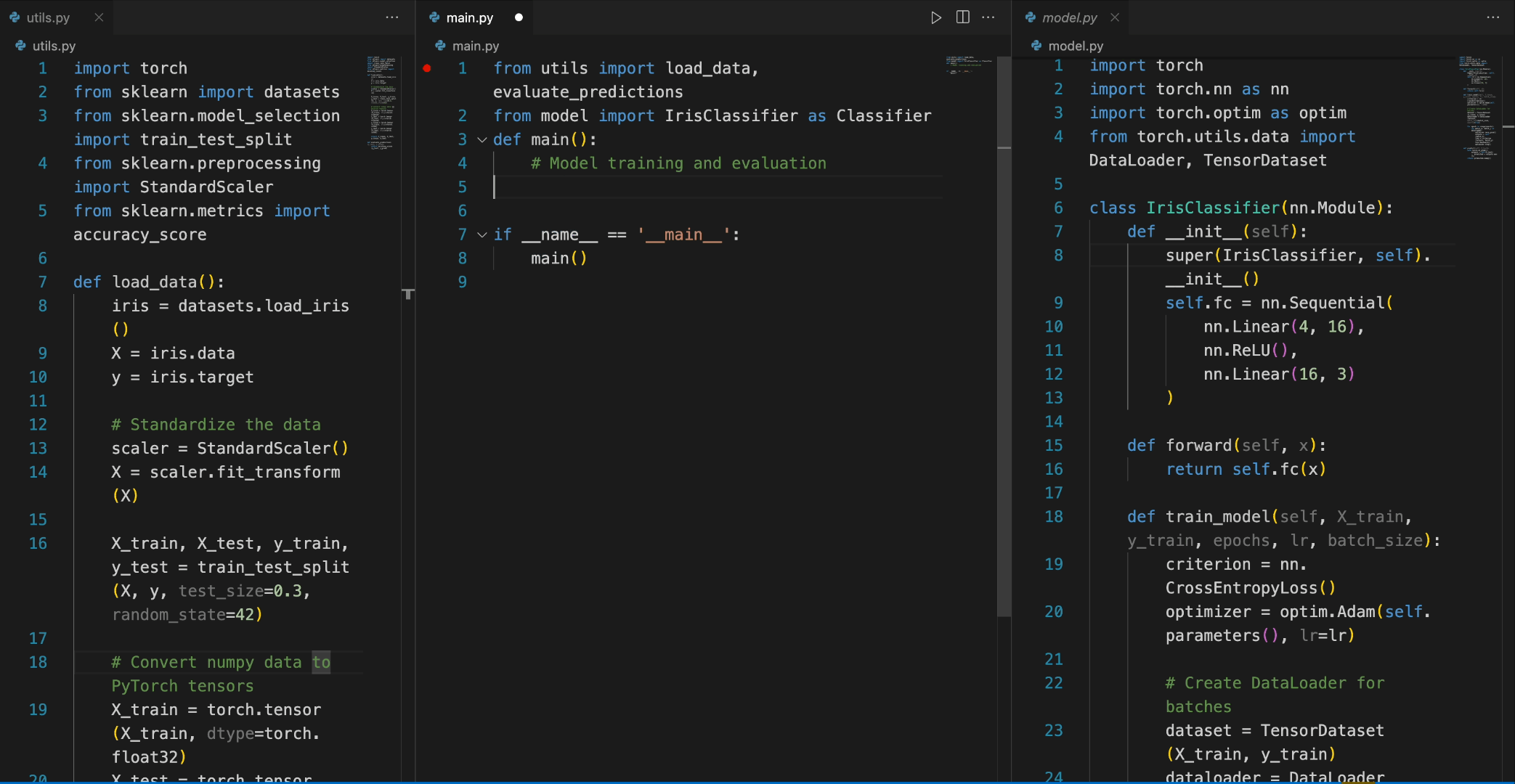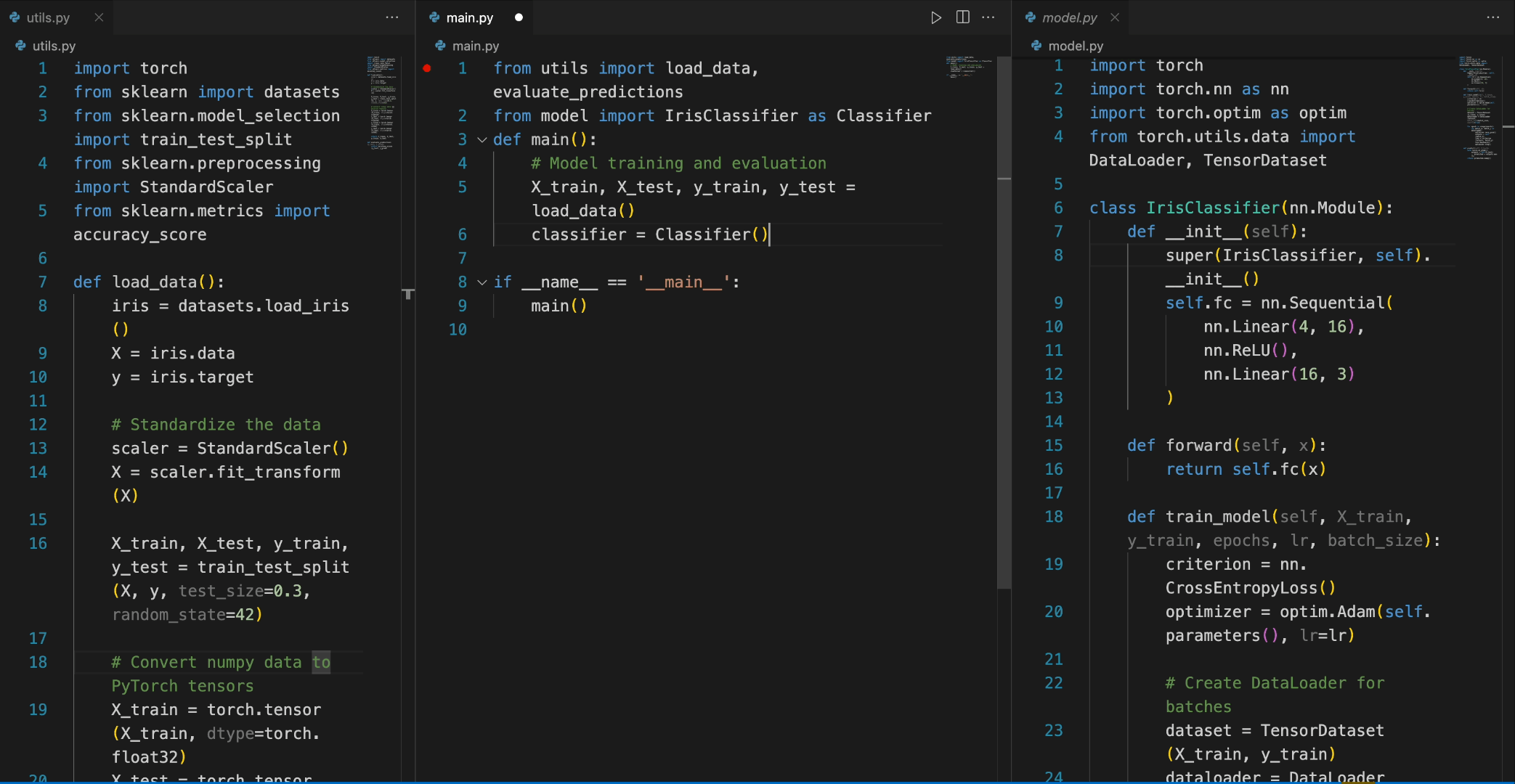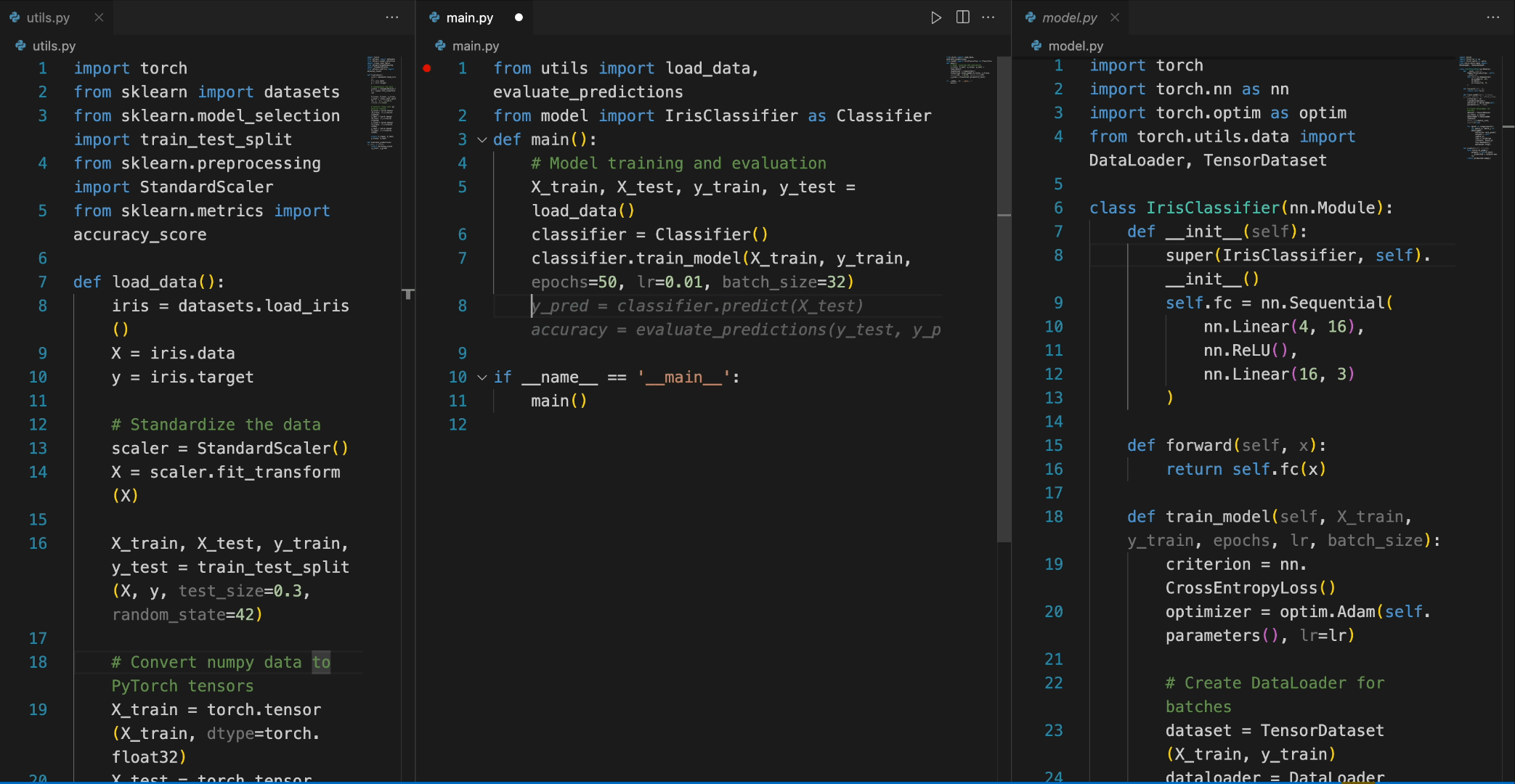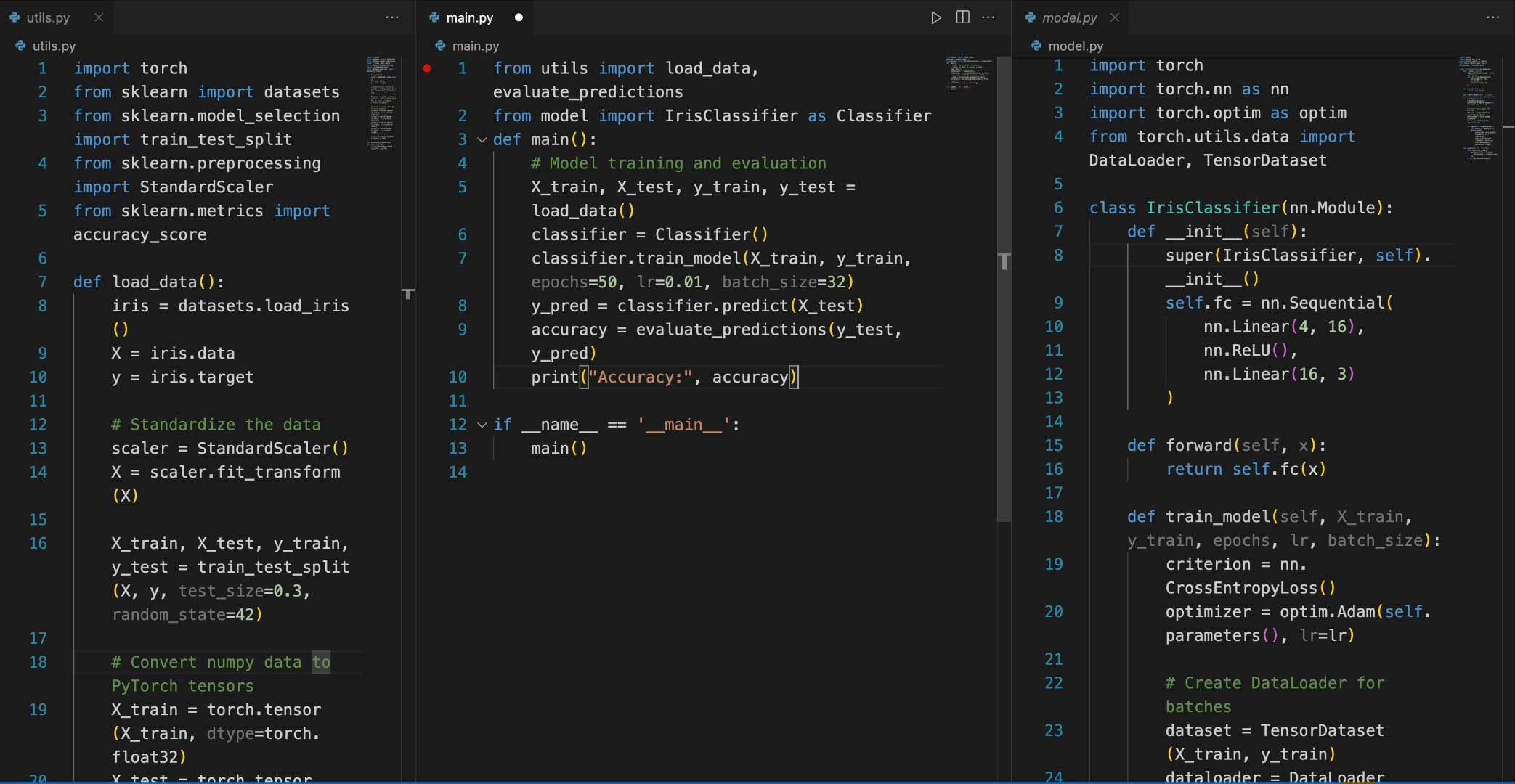
Chat功能
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("deepseek/deepseek-coder-7b")
prompt = "write a quick sort algorithm in python."
prompt = f"""Below is an instruction that describes a task, paired with an input that provides further context.\nWrite a response that appropriately completes the request.\n\n### Instruction:\nWrite a program to perform the given task.\n\nInput:\n{prompt}\n\n### Response:\n"""
inputs = tokenizer.encode(prompt, return_tensors="pt").to(device)
outputs = model.generate(**inputs, max_length=128)
print(tokenizer.decode(outputs[0]))