| Evaluation | ||
| pictures | ||
| LICENSE-CODE | ||
| LICENSE-MODEL | ||
| README.md | ||
![]()
1. Introduction of Deepseek Coder
Deepseek Coder comprises a series of advanced language models trained on both 87% code and 13% natural language in English and Chinese, with each model pre-trained on 2T tokens. We provide various sizes of the code model, ranging from 1B to 33B versions. Each model is pre-trained on project-level code corpus by employing a window size of 16K and a extra fill-in-the-blank task, to support project-level code completion and infilling. For coding capabilities, Deepseek Coder achieves state-of-the-art performance among open-source code models on various benchmarks.
-
Massive Training Data: Trained on 2T tokens, including 87% code and 13% linguistic data in both English and Chinese languages.
-
Highly Flexible & Scalable: Offered in model sizes of 1B, 7B, and 33B, enabling users to choose the setup most suitable for their requirements.
-
Superior Model Performance: State-of-the-art performance among publicly available code models on HumanEval-X, MBPP, DS-1000, and APPS datasets.
-
Advanced Code Completion Capabilities: A window size of 16K and a fill-in-the-blank task, supporting project-level code completion and infilling tasks.
2. Procedure of Data Creation and Model Training
Data Creation
- Step 1: Collecting code data from GitHub and apply the same filtering rules as StarcoderData to filter data.
- Step 2: Parsing the dependencies of files within the same repository to rearrange the file positions based on their dependencies.
- Step 3: Concatenating dependent files to form a single example and employ repo-level minhash for deduplication.
- Step 4: Further filtering out low-quality code, such as codes with syntax errors or poor readability.

Model Training
- Step 1: Initially pre-trained with a dataset consisting of 87% code, 10% code-related language (Github Markdown and StackExchange), and 3% non-code related Chinese language. This process involves 1.8T tokens and uses a 4K window size.
- Step 2: Further Pre-training using an extended 16K window size on an additional 200B tokens, resulting in foundational models.
- Step 3: Instruction Fine-tuning on 300M tokens of instruction data, resulting in instruction-tuned models.

3. Download and Setup
Deepseek Coder is initially implemented in Pytorch and trained on A100 AI Processors. We provide a torch-compatible version based on hai-llm to facilitate usage on GPU platforms. We also uploaded the checkpoint of models to the 🤗 hugginface.
Setup
Python 3.8+ / CUDA 11+ / PyTorch 2.0+ / transformers 3.34+ are required.
4. Inference and Evaluation
Here give some examples of how to use our model.
Code Completion
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("deepseek/deepseek-coder-7b")
device = 0 if torch.cuda.is_available() else -1
model = AutoModelForCausalLM.from_pretrained("deepseek/deepseek-coder-7b").to(device)
inputs = tokenizer("def hello_world():", return_tensors="pt").to(device)
outputs = model.generate(**inputs, max_length=128)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
Code Insertion
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("deepseek/deepseek-coder-7b")
device = 0 if torch.cuda.is_available() else -1
model = AutoModelForCausalLM.from_pretrained("deepseek/deepseek-coder-7b").to(device)
input_text = "<fim_prefix>def print_hello_world():\n <fim_suffix>\n print('Hello world!')<fim_middle>"
inputs = tokenizer.encode(input_text, return_tensors="pt").to(device)
outputs = model.generate(**inputs, max_length=128)
print(tokenizer.decode(outputs[0]))
Repository Level Code Completion
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("deepseek/deepseek-coder-7b")
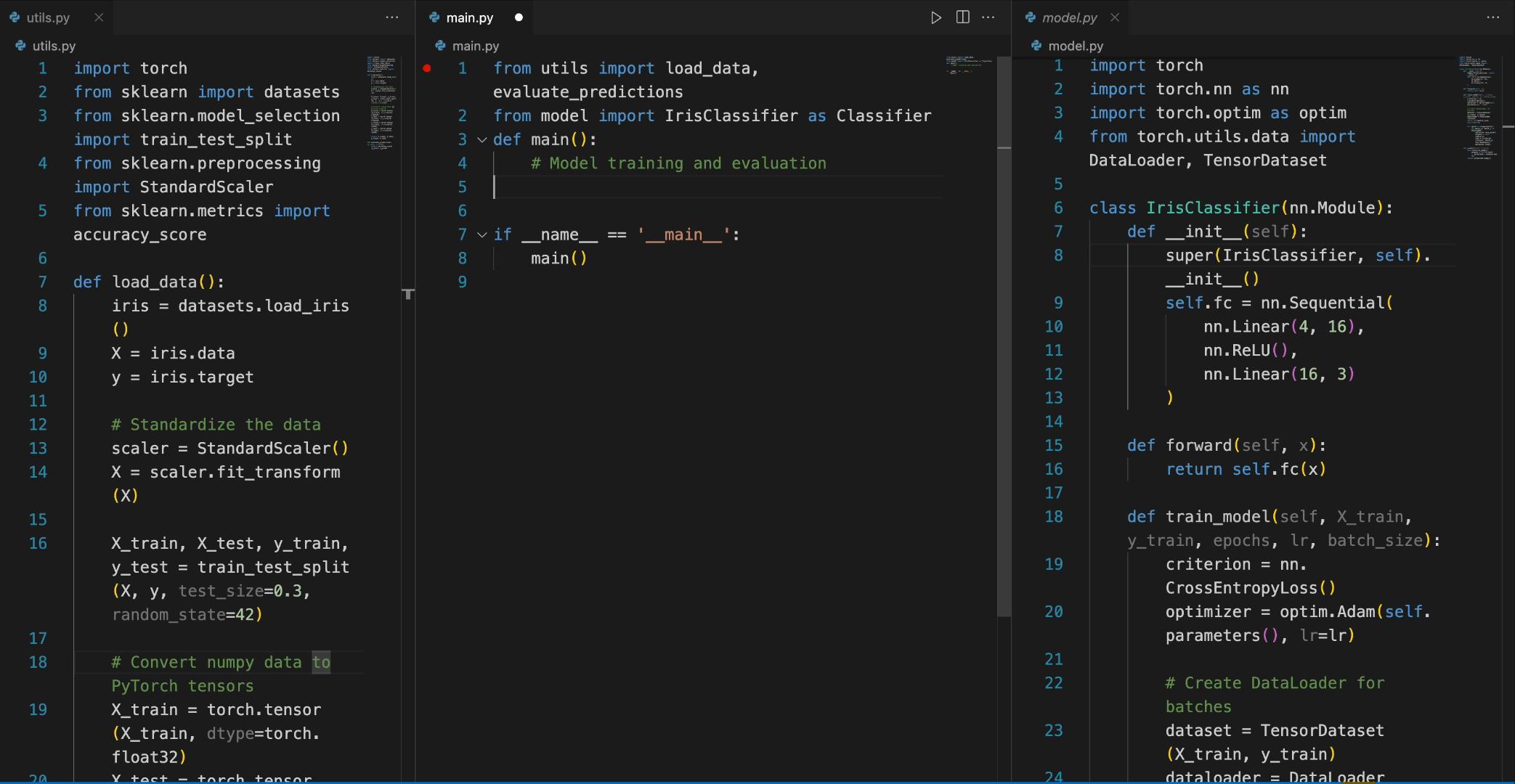
input_text = """#utils.py
import torch
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import accuracy_score
def load_data():
iris = datasets.load_iris()
X = iris.data
y = iris.target
# Standardize the data
scaler = StandardScaler()
X = scaler.fit_transform(X)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# Convert numpy data to PyTorch tensors
X_train = torch.tensor(X_train, dtype=torch.float32)
X_test = torch.tensor(X_test, dtype=torch.float32)
y_train = torch.tensor(y_train, dtype=torch.int64)
y_test = torch.tensor(y_test, dtype=torch.int64)
return X_train, X_test, y_train, y_test
def evaluate_predictions(y_test, y_pred):
return accuracy_score(y_test, y_pred)
#model.py
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, TensorDataset
class IrisClassifier(nn.Module):
def __init__(self):
super(IrisClassifier, self).__init__()
self.fc = nn.Sequential(
nn.Linear(4, 16),
nn.ReLU(),
nn.Linear(16, 3)
)
def forward(self, x):
return self.fc(x)
def train_model(self, X_train, y_train, epochs, lr, batch_size):
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(self.parameters(), lr=lr)
# Create DataLoader for batches
dataset = TensorDataset(X_train, y_train)
dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True)
for epoch in range(epochs):
for batch_X, batch_y in dataloader:
optimizer.zero_grad()
outputs = self(batch_X)
loss = criterion(outputs, batch_y)
loss.backward()
optimizer.step()
def predict(self, X_test):
with torch.no_grad():
outputs = self(X_test)
_, predicted = outputs.max(1)
return predicted.numpy()
#main.py
from utils import load_data, evaluate_predictions
from model import IrisClassifier as Classifier
def main():
# Model training and evaluation
"""
inputs = tokenizer.encode(input_text, return_tensors="pt").to(device)
outputs = model.generate(**inputs, max_length=128)
print(tokenizer.decode(outputs[0]))
Chat Model Inference
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("deepseek/deepseek-coder-7b")
prompt = "write a quick sort algorithm in python."
prompt = f"""Below is an instruction that describes a task, paired with an input that provides further context.\nWrite a response that appropriately completes the request.\n\n### Instruction:\nWrite a program to perform the given task.\n\nInput:\n{prompt}\n\n### Response:\n"""
inputs = tokenizer.encode(prompt, return_tensors="pt").to(device)
outputs = model.generate(**inputs, max_length=128)
print(tokenizer.decode(outputs[0]))