
[ Homepage] | [🤖 Chat with DeepSeek Coder] | [🤗 Models Download] | [📄 中文版]
Homepage] | [🤖 Chat with DeepSeek Coder] | [🤗 Models Download] | [📄 中文版]
### 1. Introduction of Deepseek Coder
Deepseek Coder comprises a series of code language models trained on both 87% code and 13% natural language in English and Chinese, with each model pre-trained on 2T tokens. We provide various sizes of the code model, ranging from 1B to 33B versions. Each model is pre-trained on project-level code corpus by employing a window size of 16K and a extra fill-in-the-blank task, to support project-level code completion and infilling. For coding capabilities, Deepseek Coder achieves state-of-the-art performance among open-source code models on multiple programming languages and various benchmarks.
 - **Massive Training Data**: Trained on 2T tokens, including 87% code and 13% linguistic data in both English and Chinese languages.
- **Highly Flexible & Scalable**: Offered in model sizes of 1B, 7B, and 33B, enabling users to choose the setup most suitable for their requirements.
- **Superior Model Performance**: State-of-the-art performance among publicly available code models on HumanEval, MultiPL-E, MBPP, DS-1000, and APPS benchmarks.
- **Advanced Code Completion Capabilities**: A window size of 16K and a fill-in-the-blank task, supporting project-level code completion and infilling tasks.
### 2. Procedure of Data Creation and Model Training
#### Data Creation
- Step 1: Collecting code data from GitHub and apply the same filtering rules as [StarcoderData](https://github.com/bigcode-project/bigcode-dataset) to filter data.
- Step 2: Parsing the dependencies of files within the same repository to rearrange the file positions based on their dependencies.
- Step 3: Concatenating dependent files to form a single example and employ repo-level minhash for deduplication.
- Step 4: Further filtering out low-quality code, such as codes with syntax errors or poor readability.
-
- **Massive Training Data**: Trained on 2T tokens, including 87% code and 13% linguistic data in both English and Chinese languages.
- **Highly Flexible & Scalable**: Offered in model sizes of 1B, 7B, and 33B, enabling users to choose the setup most suitable for their requirements.
- **Superior Model Performance**: State-of-the-art performance among publicly available code models on HumanEval, MultiPL-E, MBPP, DS-1000, and APPS benchmarks.
- **Advanced Code Completion Capabilities**: A window size of 16K and a fill-in-the-blank task, supporting project-level code completion and infilling tasks.
### 2. Procedure of Data Creation and Model Training
#### Data Creation
- Step 1: Collecting code data from GitHub and apply the same filtering rules as [StarcoderData](https://github.com/bigcode-project/bigcode-dataset) to filter data.
- Step 2: Parsing the dependencies of files within the same repository to rearrange the file positions based on their dependencies.
- Step 3: Concatenating dependent files to form a single example and employ repo-level minhash for deduplication.
- Step 4: Further filtering out low-quality code, such as codes with syntax errors or poor readability.
-  #### Model Training
- Step 1: Initially pre-trained with a dataset consisting of 87% code, 10% code-related language (Github Markdown and StackExchange), and 3% non-code related Chinese language. Models are pre-trained using 1.8T tokens and a 4K window size in this step.
- Step 2: Further Pre-training using an extended 16K window size on an additional 200B tokens, resulting in foundational models (**DeepSeek-Coder-Base**).
- Step 3: Instruction Fine-tuning on 2B tokens of instruction data, resulting in instruction-tuned models (**DeepSeek-Coder-Instruct**).
#### Model Training
- Step 1: Initially pre-trained with a dataset consisting of 87% code, 10% code-related language (Github Markdown and StackExchange), and 3% non-code related Chinese language. Models are pre-trained using 1.8T tokens and a 4K window size in this step.
- Step 2: Further Pre-training using an extended 16K window size on an additional 200B tokens, resulting in foundational models (**DeepSeek-Coder-Base**).
- Step 3: Instruction Fine-tuning on 2B tokens of instruction data, resulting in instruction-tuned models (**DeepSeek-Coder-Instruct**).
 ### 3. Download and Setup
We provide a torch-compatible version based on hai-llm to facilitate usage on GPU platforms, and you can download model checkpoints from [huggingface](https://huggingface.co/deepseek-ai).
#### Setup
Python 3.8+ / CUDA 11+ / PyTorch 2.0+ / transformers 3.34+ are required.
### 4. Inference and Evaluation
Here give some examples of how to use our model.
#### 1)Code Completion
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
tokenizer = AutoTokenizer.from_pretrained("deepseek/deepseek-coder-7b-base", trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("deepseek/deepseek-coder-7b-base", trust_remote_code=True).cuda()
input_text = "#write a quick sort algorithm"
inputs = tokenizer(input_text, return_tensors="pt").cuda()
outputs = model.generate(**inputs, max_length=128)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
```
This code will output the following result:
```
def quick_sort(arr):
if len(arr) <= 1:
return arr
pivot = arr[0]
left = []
right = []
for i in range(1, len(arr)):
if arr[i] < pivot:
left.append(arr[i])
else:
right.append(arr[i])
return quick_sort(left) + [pivot] + quick_sort(right)
```
#### 2)Code Insertion
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
tokenizer = AutoTokenizer.from_pretrained("deepseek/deepseek-coder-7b-base", trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("deepseek/deepseek-coder-7b-base", trust_remote_code=True).cuda()
input_text = """def quick_sort(arr):
if len(arr) <= 1:
return arr
pivot = arr[0]
left = []
right = []
if arr[i] < pivot:
left.append(arr[i])
else:
right.append(arr[i])
return quick_sort(left) + [pivot] + quick_sort(right)"""
inputs = tokenizer(input_text, return_tensors="pt").cuda()
outputs = model.generate(**inputs, max_length=128)
print(tokenizer.decode(outputs[0], skip_special_tokens=True)[len(input_text):])
```
This code will output the following result:
```
for i in range(1, len(arr)):
```
#### 3)Repository Level Code Completion
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("deepseek/deepseek-coder-7b-base", trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("deepseek/deepseek-coder-7b-base", trust_remote_code=True).cuda()
input_text = """#utils.py
import torch
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import accuracy_score
def load_data():
iris = datasets.load_iris()
X = iris.data
y = iris.target
# Standardize the data
scaler = StandardScaler()
X = scaler.fit_transform(X)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# Convert numpy data to PyTorch tensors
X_train = torch.tensor(X_train, dtype=torch.float32)
X_test = torch.tensor(X_test, dtype=torch.float32)
y_train = torch.tensor(y_train, dtype=torch.int64)
y_test = torch.tensor(y_test, dtype=torch.int64)
return X_train, X_test, y_train, y_test
def evaluate_predictions(y_test, y_pred):
return accuracy_score(y_test, y_pred)
#model.py
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, TensorDataset
class IrisClassifier(nn.Module):
def __init__(self):
super(IrisClassifier, self).__init__()
self.fc = nn.Sequential(
nn.Linear(4, 16),
nn.ReLU(),
nn.Linear(16, 3)
)
def forward(self, x):
return self.fc(x)
def train_model(self, X_train, y_train, epochs, lr, batch_size):
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(self.parameters(), lr=lr)
# Create DataLoader for batches
dataset = TensorDataset(X_train, y_train)
dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True)
for epoch in range(epochs):
for batch_X, batch_y in dataloader:
optimizer.zero_grad()
outputs = self(batch_X)
loss = criterion(outputs, batch_y)
loss.backward()
optimizer.step()
def predict(self, X_test):
with torch.no_grad():
outputs = self(X_test)
_, predicted = outputs.max(1)
return predicted.numpy()
#main.py
from utils import load_data, evaluate_predictions
from model import IrisClassifier as Classifier
def main():
# Model training and evaluation
"""
inputs = tokenizer(input_text, return_tensors="pt").cuda()
outputs = model.generate(**inputs, max_new_tokens=140)
print(tokenizer.decode(outputs[0]))
```
---
In the following scenario, the Deepseek-Coder 7B model effectively calls a class **IrisClassifier** and its member function from the `model.py` file, and also utilizes functions from the `utils.py` file, to correctly complete the **main** function in`main.py` file for model training and evaluation.
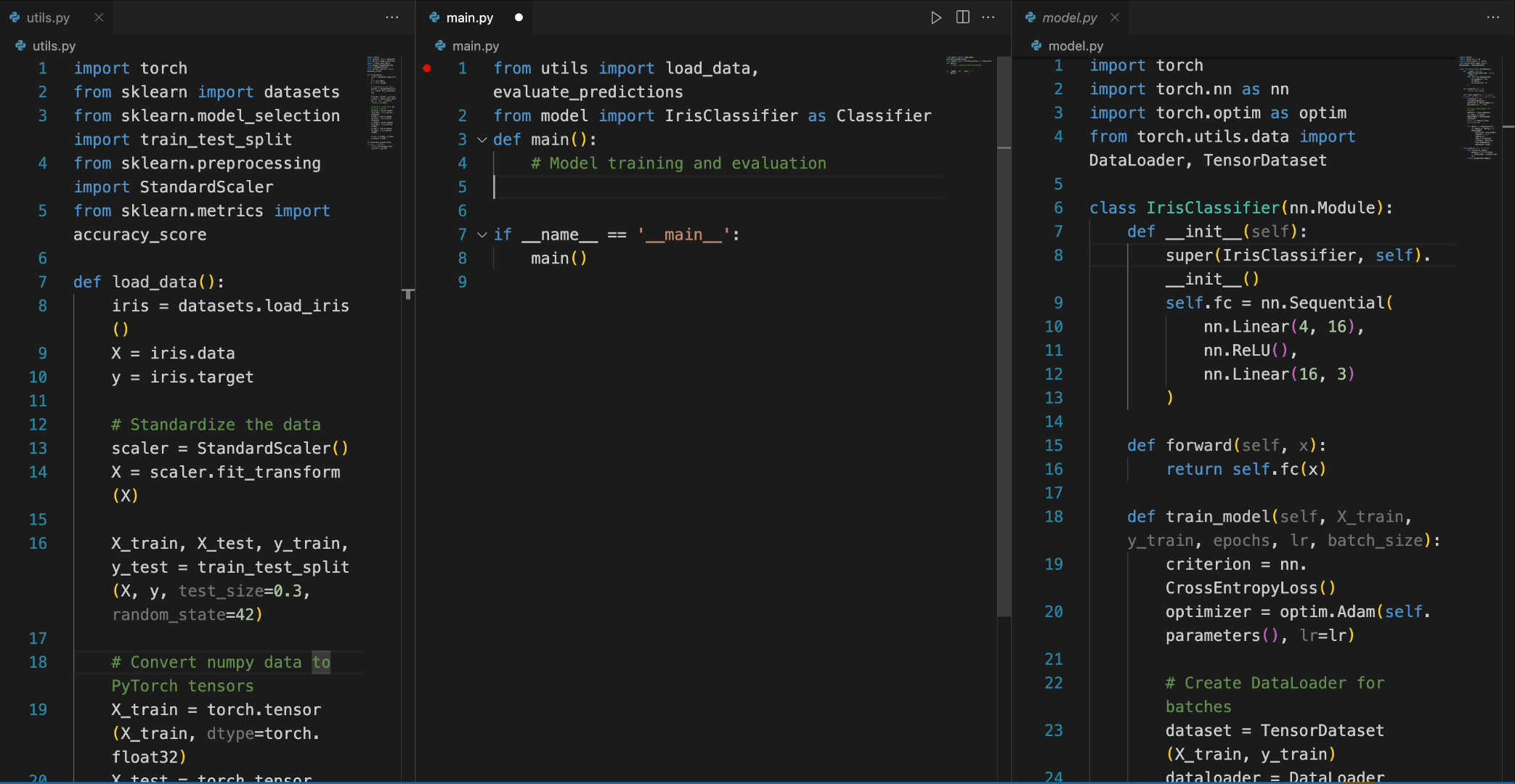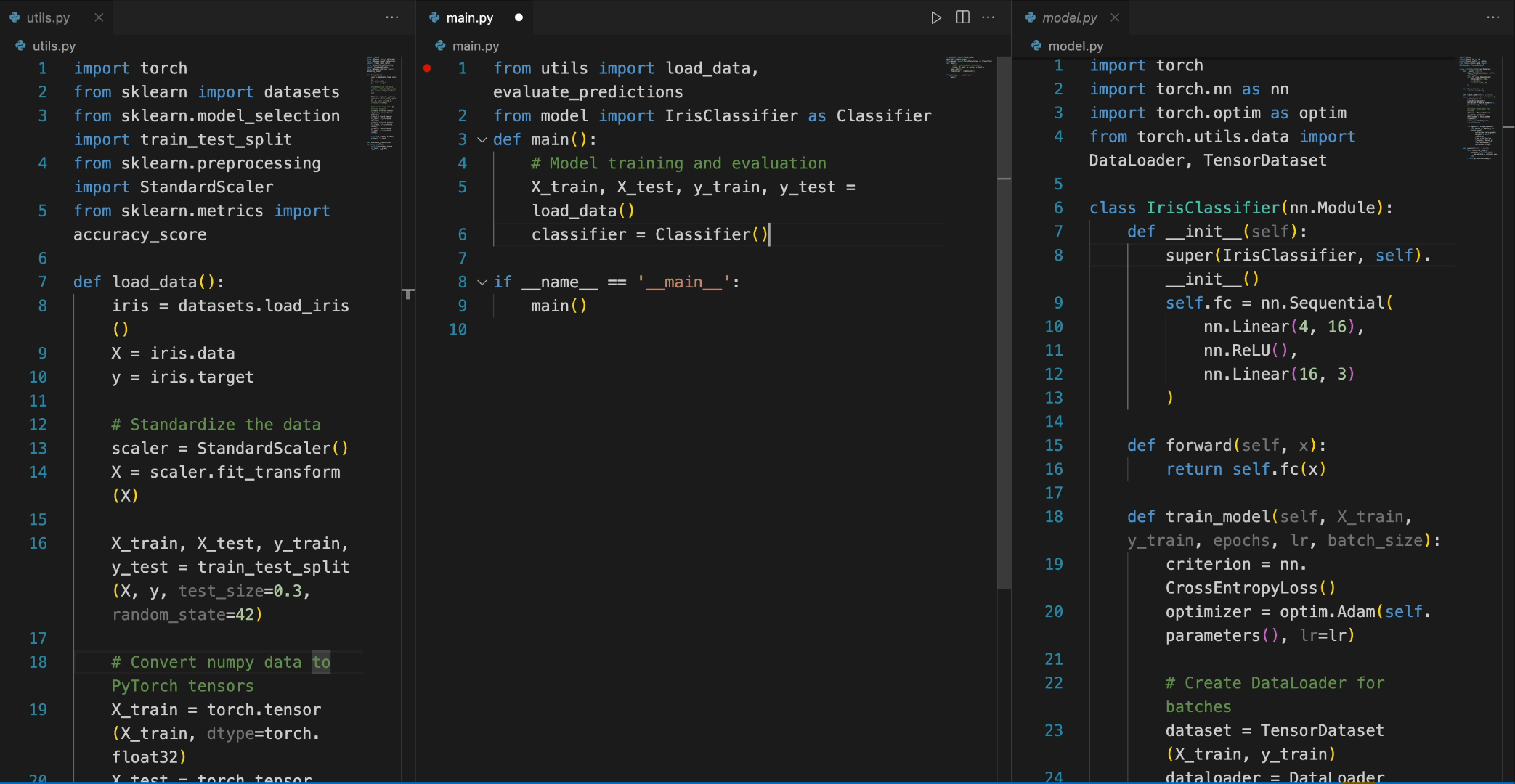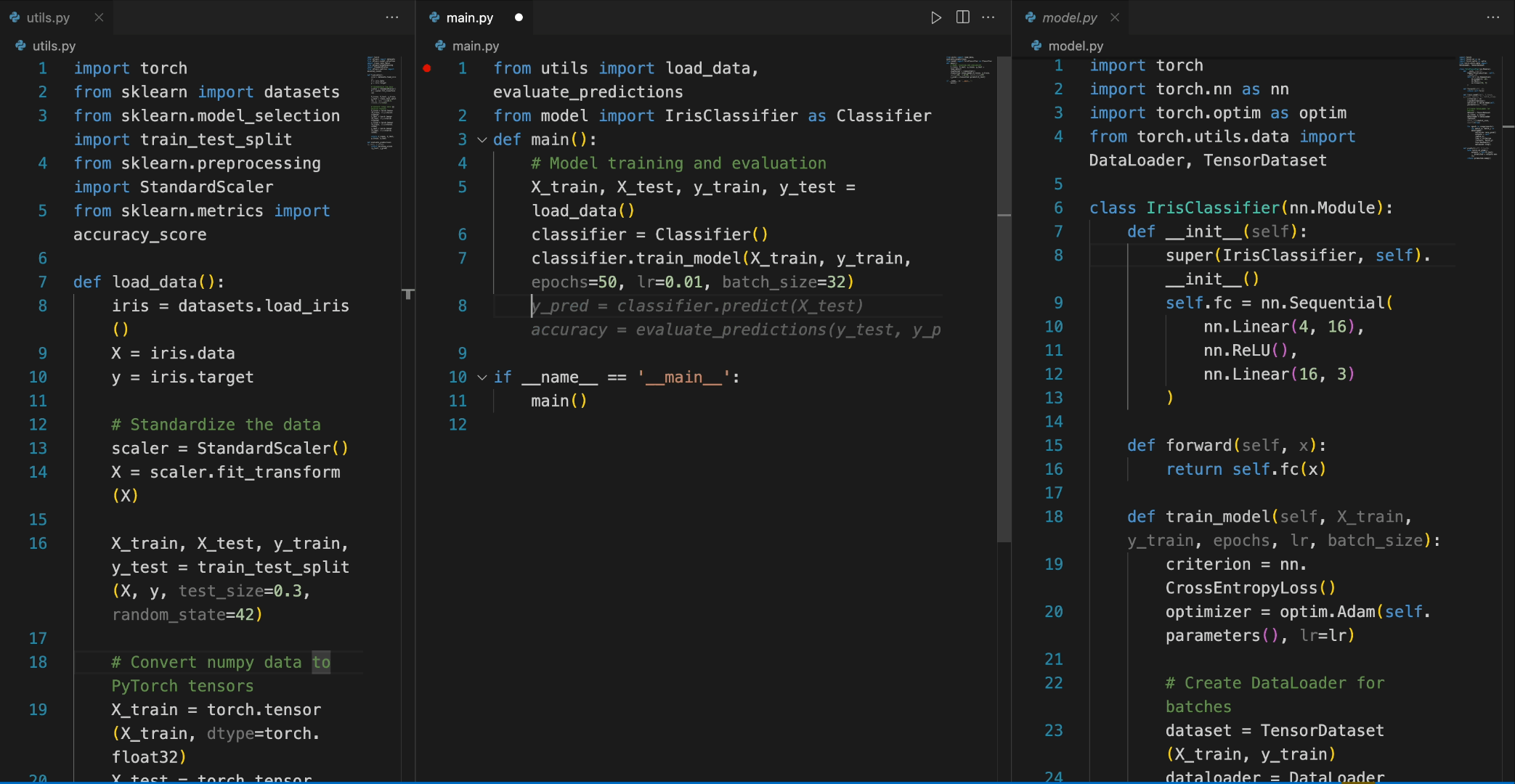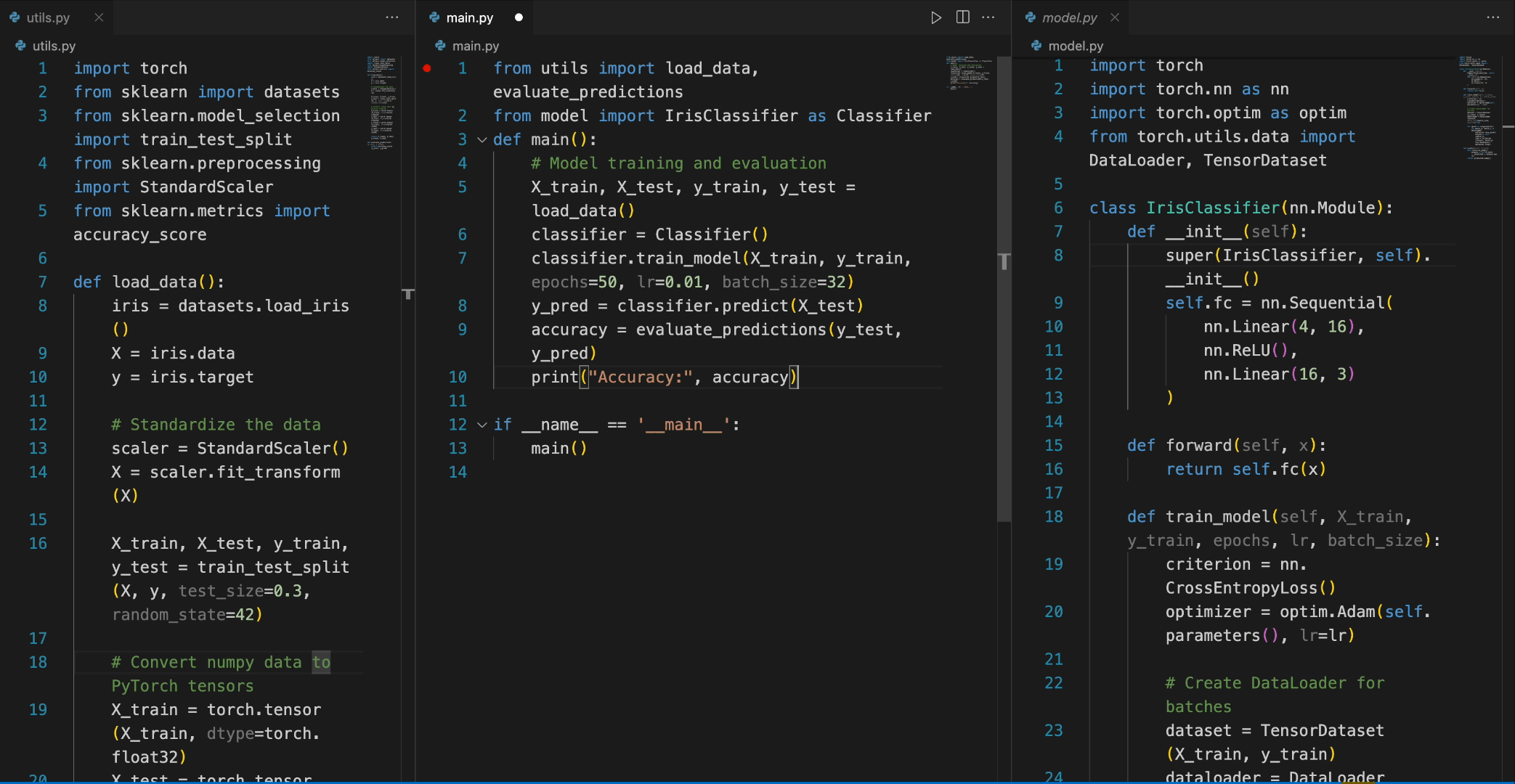
#### 4)Chat Model Inference
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("deepseek/deepseek-coder-7b-base", trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("deepseek/deepseek-coder-7b-base", trust_remote_code=True).cuda()
prompt = "write a quick sort algorithm in python."
prompt = f"""Below is an instruction that describes a task, paired with an input that provides further context.\nWrite a response that appropriately completes the request.\n\n### Instruction:\nWrite a program to perform the given task.\n\nInput:\n{prompt}\n\n### Response:\n"""
inputs = tokenizer.encode(prompt, return_tensors="pt").cuda()
outputs = model.generate(**inputs, max_length=128)
print(tokenizer.decode(outputs[0]))
```
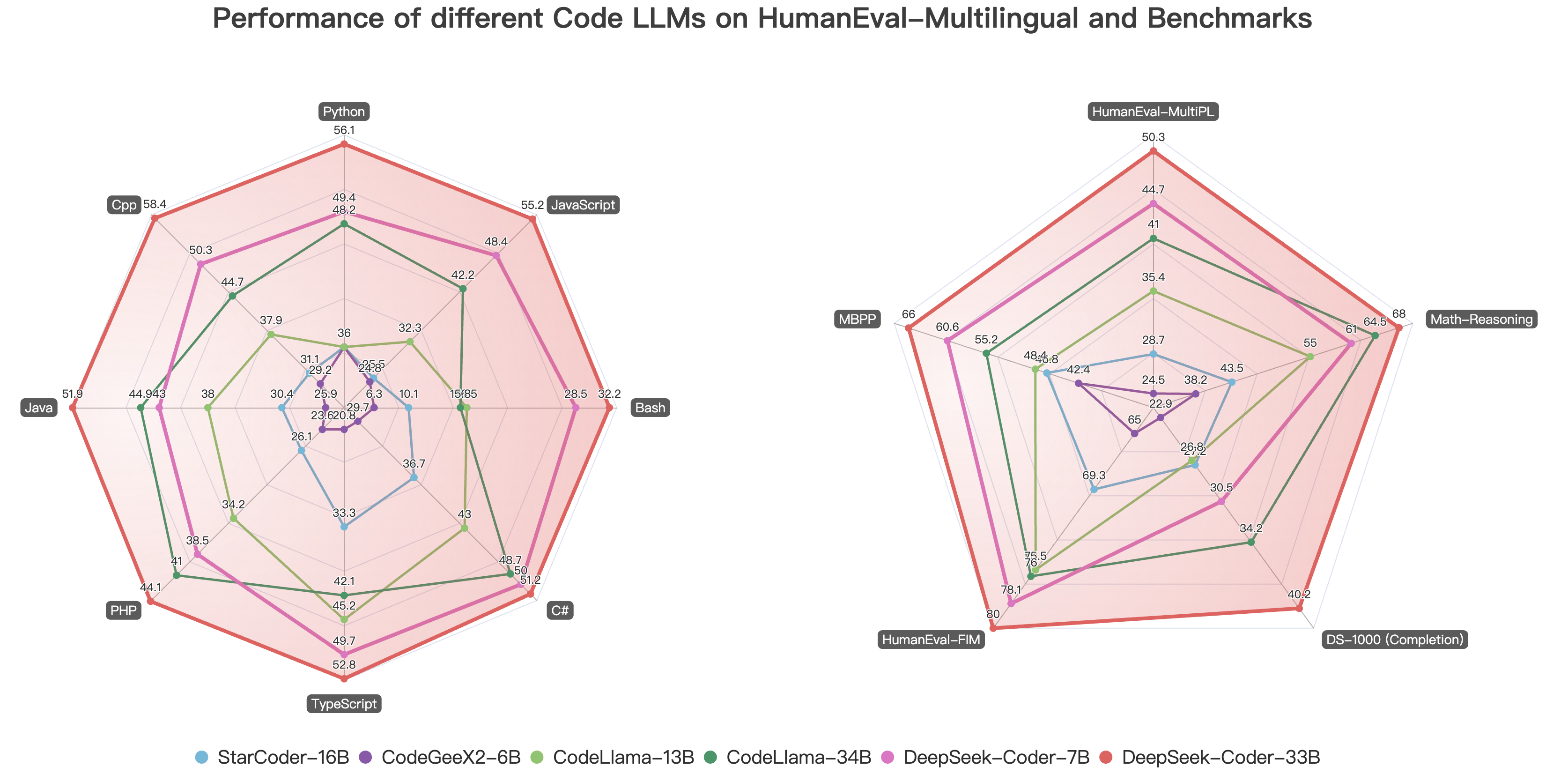
### 5. Evaluation Results
The reproducible code for the following evaluation results can be found in the Evaluation directory.
#### 1) [HumanEval](https://github.com/deepseek-ai/deepseek-coder/tree/main/Evaluation/HumanEval)
Multilingual Base Models
| Model | Size | Python | C++ | Java | PHP | TS | C# | Bash | JS | Avg |
| ------------------- | ---- | ------ | ----- | ----- | ----- | ----- | ----- | ----- | ----- | ----- |
| code-cushman-001 | 12B | 33.5% | 31.9% | 30.6% | 28.9% | 31.3% | 22.1% | 11.7% | - | - |
| CodeShell | 7B | 35.4% | 32.9% | 34.2% | 31.7% | 30.2% | 38.0% | 7.0% | 33.5% | 30.4% |
| CodeGeeX2 | 6B | 36.0% | 29.2% | 25.9% | 23.6% | 20.8% | 29.7% | 6.3% | 24.8% | 24.5% |
| StarCoderBase | 16B | 31.7% | 31.1% | 28.5% | 25.4% | 34.0% | 34.8% | 8.9% | 29.8% | 28.0% |
| CodeLLama | 7B | 31.7% | 29.8% | 34.2% | 23.6% | 36.5% | 36.7% | 12.0% | 29.2% | 29.2% |
| CodeLLama | 13B | 36.0% | 37.9% | 38.0% | 34.2% | 45.2% | 43.0% | 16.5% | 32.3% | 35.4% |
| CodeLLama | 34B | 48.2% | 44.7% | 44.9% | 41.0% | 42.1% | 48.7% | 15.8% | 42.2% | 41.0% |
| | | | | | | | | | | |
| DeepSeek-Coder-Base | 1B | 34.8% | 31.1% | 32.3% | 24.2% | 28.9% | 36.7% | 10.1% | 28.6% | 28.3% |
| DeepSeek-Coder-Base | 7B | 49.4% | 50.3% | 43.0% | 38.5% | 49.7% | 50.0% | 28.5% | 48.4% | 44.7% |
| DeepSeek-Coder-Base | 33B | - | - | - | - | - | - | - | - | - |
Instruction-Tuned Models
| Model | Size | Python | C++ | Java | PHP | TS | C# | Bash | JS | Avg |
| ------------------- | ---- | ------ | ----- | ----- | ----- | ----- | ----- | ----- | ----- | ----- |
| ChatGPT | - | 70.7% | 50.3% | 54.5% | 52.2% | 62.3% | 64.6% | 34.8% | 60.9% | 52.2% |
| GPT-4 | - | 82.3% | 70.2% | 74.8% | 70.8% | 73.0% | 77.9% | 51.3% | 83.2% | 72.9% |
| WizardCoder | 16B | 51.8% | 41.6% | 41.1% | 42.2% | 44.7% | 46.8% | 12.7% | 42.8% | 40.5% |
| Phind-CodeLlama | 34B | - | - | - | - | - | - | - | - | - |
| | | | | | | | | | | |
| DeepSeek-Coder-Instruct | 1B | - | - | - | - | - | - | - | - | - |
| DeepSeek-Coder-Instruct | 7B | - | - | - | - | - | - | - | - | - |
| DeepSeek-Coder-Instruct | 33B | - | - | - | - | - | - | - | - | - |
#### 2) [Math Reasoning](https://github.com/deepseek-ai/deepseek-coder/tree/main/Evaluation/PAL-Math)
Multilingual Base Models
| Model | Size | GSM8k | MATH | GSM-Hard | SVAMP | TabMWP | ASDiv | MAWPS | Avg |
| -------------- | ---- | ----- | ----- | -------- | ----- | ------ | ----- | ----- | ----- |
| CodeShell | 7B | 17.0% | 9.1% | 18.2% | 45.6% | 29.6% | 46.6% | 56.8% | 31.8% |
| CodeGeex-2 | 7B | 23.6% | 9.6% | 22.4% | 48.0% | 47.2% | 46.9% | 66.0% | 37.7% |
| StarCoder-Base | 16B | 27.3% | 11.5% | 24.2% | 44.0% | 45.6% | 54.9% | 73.4% | 40.1% |
| CodeLLama-Base | 7B | 36.4% | 12.3% | 29.7% | 57.6% | 58.4% | 59.6% | 82.6% | 48.0% |
| CodeLLama-Base | 13B | 44.2% | 15.5% | 42.4% | 65.6% | 61.6% | 65.3% | 85.3% | 54.3% |
| CodeLLama-Base | 34B | 58.2% | 22.1% | 55.2% | 77.2% | 69.6% | 70.0% | 92.8% | 63.6% |
| | | | | | | | | | |
| DeepSeek-Coder-Base | 1B | 17.0% | 13.4% | 13.3% | 39.2% | 42.4% | 44.8% | 66.0% | 33.7% |
| DeepSeek-Coder-Base | 7B | 46.0% | 20.6% | 40.0% | 67.2% | 71.2% | 67.1% | 89.1% | 57.3% |
| DeepSeek-Coder-Base | 33B | - | - | - | - | - | - | - | - |
Instruction-Tuned Models
| Model | Size | GSM8k | MATH | GSM-Hard | SVAMP | TabMWP | ASDiv | MAWPS | Avg |
| ------------- | ---- | ----- | ----- | -------- | ----- | ------ | ----- | ----- | ----- |
| ChatGPT | - | 78.6% | 38.7% | 67.6% | 77.8% | 79.9% | 81.0% | 89.4% | 73.3% |
| GPT-4 | - | 94.2% | 51.8% | 77.6% | 94.8% | 95.9% | 92.6% | 97.7% | 86.4% |
| | | | | | | | | | |
| DeepSeek-Coder-Instruct | 1B | - | - | - | - | - | - | - | - |
| DeepSeek-Coder-Instruct | 7B | - | - | - | - | - | - | - | - |
| DeepSeek-Coder-Instruct | 33B | - | - | - | - | - | - | - | - |
### 6. Lincense
### 7. Contact
If you have any questions, please raise an issue or contact us at [agi_code@deepseek.com](mailto:agi_code@deepseek.com).
### 3. Download and Setup
We provide a torch-compatible version based on hai-llm to facilitate usage on GPU platforms, and you can download model checkpoints from [huggingface](https://huggingface.co/deepseek-ai).
#### Setup
Python 3.8+ / CUDA 11+ / PyTorch 2.0+ / transformers 3.34+ are required.
### 4. Inference and Evaluation
Here give some examples of how to use our model.
#### 1)Code Completion
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
tokenizer = AutoTokenizer.from_pretrained("deepseek/deepseek-coder-7b-base", trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("deepseek/deepseek-coder-7b-base", trust_remote_code=True).cuda()
input_text = "#write a quick sort algorithm"
inputs = tokenizer(input_text, return_tensors="pt").cuda()
outputs = model.generate(**inputs, max_length=128)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
```
This code will output the following result:
```
def quick_sort(arr):
if len(arr) <= 1:
return arr
pivot = arr[0]
left = []
right = []
for i in range(1, len(arr)):
if arr[i] < pivot:
left.append(arr[i])
else:
right.append(arr[i])
return quick_sort(left) + [pivot] + quick_sort(right)
```
#### 2)Code Insertion
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
tokenizer = AutoTokenizer.from_pretrained("deepseek/deepseek-coder-7b-base", trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("deepseek/deepseek-coder-7b-base", trust_remote_code=True).cuda()
input_text = """def quick_sort(arr):
if len(arr) <= 1:
return arr
pivot = arr[0]
left = []
right = []
if arr[i] < pivot:
left.append(arr[i])
else:
right.append(arr[i])
return quick_sort(left) + [pivot] + quick_sort(right)"""
inputs = tokenizer(input_text, return_tensors="pt").cuda()
outputs = model.generate(**inputs, max_length=128)
print(tokenizer.decode(outputs[0], skip_special_tokens=True)[len(input_text):])
```
This code will output the following result:
```
for i in range(1, len(arr)):
```
#### 3)Repository Level Code Completion
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("deepseek/deepseek-coder-7b-base", trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("deepseek/deepseek-coder-7b-base", trust_remote_code=True).cuda()
input_text = """#utils.py
import torch
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import accuracy_score
def load_data():
iris = datasets.load_iris()
X = iris.data
y = iris.target
# Standardize the data
scaler = StandardScaler()
X = scaler.fit_transform(X)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# Convert numpy data to PyTorch tensors
X_train = torch.tensor(X_train, dtype=torch.float32)
X_test = torch.tensor(X_test, dtype=torch.float32)
y_train = torch.tensor(y_train, dtype=torch.int64)
y_test = torch.tensor(y_test, dtype=torch.int64)
return X_train, X_test, y_train, y_test
def evaluate_predictions(y_test, y_pred):
return accuracy_score(y_test, y_pred)
#model.py
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, TensorDataset
class IrisClassifier(nn.Module):
def __init__(self):
super(IrisClassifier, self).__init__()
self.fc = nn.Sequential(
nn.Linear(4, 16),
nn.ReLU(),
nn.Linear(16, 3)
)
def forward(self, x):
return self.fc(x)
def train_model(self, X_train, y_train, epochs, lr, batch_size):
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(self.parameters(), lr=lr)
# Create DataLoader for batches
dataset = TensorDataset(X_train, y_train)
dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True)
for epoch in range(epochs):
for batch_X, batch_y in dataloader:
optimizer.zero_grad()
outputs = self(batch_X)
loss = criterion(outputs, batch_y)
loss.backward()
optimizer.step()
def predict(self, X_test):
with torch.no_grad():
outputs = self(X_test)
_, predicted = outputs.max(1)
return predicted.numpy()
#main.py
from utils import load_data, evaluate_predictions
from model import IrisClassifier as Classifier
def main():
# Model training and evaluation
"""
inputs = tokenizer(input_text, return_tensors="pt").cuda()
outputs = model.generate(**inputs, max_new_tokens=140)
print(tokenizer.decode(outputs[0]))
```
---
In the following scenario, the Deepseek-Coder 7B model effectively calls a class **IrisClassifier** and its member function from the `model.py` file, and also utilizes functions from the `utils.py` file, to correctly complete the **main** function in`main.py` file for model training and evaluation.

#### 4)Chat Model Inference
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("deepseek/deepseek-coder-7b-base", trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("deepseek/deepseek-coder-7b-base", trust_remote_code=True).cuda()
prompt = "write a quick sort algorithm in python."
prompt = f"""Below is an instruction that describes a task, paired with an input that provides further context.\nWrite a response that appropriately completes the request.\n\n### Instruction:\nWrite a program to perform the given task.\n\nInput:\n{prompt}\n\n### Response:\n"""
inputs = tokenizer.encode(prompt, return_tensors="pt").cuda()
outputs = model.generate(**inputs, max_length=128)
print(tokenizer.decode(outputs[0]))
```
### 5. Evaluation Results
The reproducible code for the following evaluation results can be found in the Evaluation directory.
#### 1) [HumanEval](https://github.com/deepseek-ai/deepseek-coder/tree/main/Evaluation/HumanEval)
Multilingual Base Models
| Model | Size | Python | C++ | Java | PHP | TS | C# | Bash | JS | Avg |
| ------------------- | ---- | ------ | ----- | ----- | ----- | ----- | ----- | ----- | ----- | ----- |
| code-cushman-001 | 12B | 33.5% | 31.9% | 30.6% | 28.9% | 31.3% | 22.1% | 11.7% | - | - |
| CodeShell | 7B | 35.4% | 32.9% | 34.2% | 31.7% | 30.2% | 38.0% | 7.0% | 33.5% | 30.4% |
| CodeGeeX2 | 6B | 36.0% | 29.2% | 25.9% | 23.6% | 20.8% | 29.7% | 6.3% | 24.8% | 24.5% |
| StarCoderBase | 16B | 31.7% | 31.1% | 28.5% | 25.4% | 34.0% | 34.8% | 8.9% | 29.8% | 28.0% |
| CodeLLama | 7B | 31.7% | 29.8% | 34.2% | 23.6% | 36.5% | 36.7% | 12.0% | 29.2% | 29.2% |
| CodeLLama | 13B | 36.0% | 37.9% | 38.0% | 34.2% | 45.2% | 43.0% | 16.5% | 32.3% | 35.4% |
| CodeLLama | 34B | 48.2% | 44.7% | 44.9% | 41.0% | 42.1% | 48.7% | 15.8% | 42.2% | 41.0% |
| | | | | | | | | | | |
| DeepSeek-Coder-Base | 1B | 34.8% | 31.1% | 32.3% | 24.2% | 28.9% | 36.7% | 10.1% | 28.6% | 28.3% |
| DeepSeek-Coder-Base | 7B | 49.4% | 50.3% | 43.0% | 38.5% | 49.7% | 50.0% | 28.5% | 48.4% | 44.7% |
| DeepSeek-Coder-Base | 33B | - | - | - | - | - | - | - | - | - |
Instruction-Tuned Models
| Model | Size | Python | C++ | Java | PHP | TS | C# | Bash | JS | Avg |
| ------------------- | ---- | ------ | ----- | ----- | ----- | ----- | ----- | ----- | ----- | ----- |
| ChatGPT | - | 70.7% | 50.3% | 54.5% | 52.2% | 62.3% | 64.6% | 34.8% | 60.9% | 52.2% |
| GPT-4 | - | 82.3% | 70.2% | 74.8% | 70.8% | 73.0% | 77.9% | 51.3% | 83.2% | 72.9% |
| WizardCoder | 16B | 51.8% | 41.6% | 41.1% | 42.2% | 44.7% | 46.8% | 12.7% | 42.8% | 40.5% |
| Phind-CodeLlama | 34B | - | - | - | - | - | - | - | - | - |
| | | | | | | | | | | |
| DeepSeek-Coder-Instruct | 1B | - | - | - | - | - | - | - | - | - |
| DeepSeek-Coder-Instruct | 7B | - | - | - | - | - | - | - | - | - |
| DeepSeek-Coder-Instruct | 33B | - | - | - | - | - | - | - | - | - |
#### 2) [Math Reasoning](https://github.com/deepseek-ai/deepseek-coder/tree/main/Evaluation/PAL-Math)
Multilingual Base Models
| Model | Size | GSM8k | MATH | GSM-Hard | SVAMP | TabMWP | ASDiv | MAWPS | Avg |
| -------------- | ---- | ----- | ----- | -------- | ----- | ------ | ----- | ----- | ----- |
| CodeShell | 7B | 17.0% | 9.1% | 18.2% | 45.6% | 29.6% | 46.6% | 56.8% | 31.8% |
| CodeGeex-2 | 7B | 23.6% | 9.6% | 22.4% | 48.0% | 47.2% | 46.9% | 66.0% | 37.7% |
| StarCoder-Base | 16B | 27.3% | 11.5% | 24.2% | 44.0% | 45.6% | 54.9% | 73.4% | 40.1% |
| CodeLLama-Base | 7B | 36.4% | 12.3% | 29.7% | 57.6% | 58.4% | 59.6% | 82.6% | 48.0% |
| CodeLLama-Base | 13B | 44.2% | 15.5% | 42.4% | 65.6% | 61.6% | 65.3% | 85.3% | 54.3% |
| CodeLLama-Base | 34B | 58.2% | 22.1% | 55.2% | 77.2% | 69.6% | 70.0% | 92.8% | 63.6% |
| | | | | | | | | | |
| DeepSeek-Coder-Base | 1B | 17.0% | 13.4% | 13.3% | 39.2% | 42.4% | 44.8% | 66.0% | 33.7% |
| DeepSeek-Coder-Base | 7B | 46.0% | 20.6% | 40.0% | 67.2% | 71.2% | 67.1% | 89.1% | 57.3% |
| DeepSeek-Coder-Base | 33B | - | - | - | - | - | - | - | - |
Instruction-Tuned Models
| Model | Size | GSM8k | MATH | GSM-Hard | SVAMP | TabMWP | ASDiv | MAWPS | Avg |
| ------------- | ---- | ----- | ----- | -------- | ----- | ------ | ----- | ----- | ----- |
| ChatGPT | - | 78.6% | 38.7% | 67.6% | 77.8% | 79.9% | 81.0% | 89.4% | 73.3% |
| GPT-4 | - | 94.2% | 51.8% | 77.6% | 94.8% | 95.9% | 92.6% | 97.7% | 86.4% |
| | | | | | | | | | |
| DeepSeek-Coder-Instruct | 1B | - | - | - | - | - | - | - | - |
| DeepSeek-Coder-Instruct | 7B | - | - | - | - | - | - | - | - |
| DeepSeek-Coder-Instruct | 33B | - | - | - | - | - | - | - | - |
### 6. Lincense
### 7. Contact
If you have any questions, please raise an issue or contact us at [agi_code@deepseek.com](mailto:agi_code@deepseek.com).